
"a man wearing a hat"

"an oil painting of a snowy mountain village"

"a rocket ship"
A) Generate various images with diffusion models, including visual anagrams and hybrid images.
B) Create our own diffusion model and train it on MNIST dataset.
I chose the seed 508312 for this project. These are some example images generated with given model and num_inference_steps=20:






As we can see the higher num_inference_steps the better are the generated results. We can also see a rough correspondence between detailness of a picture and the length of the prompt: the lengthier the prompt the more detailed is the image.
Forward process is adding noise to an image to some level t, I used the following formula to implement it 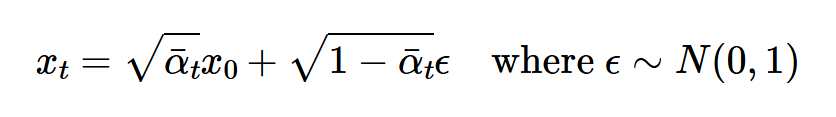 .
Here are some results of campanile at different noise levels:
.
Here are some results of campanile at different noise levels:




I tried to denoise images by applying Gaussian filter, here are some(bad looking) results:



Here we remove the noise predicted by a model from a noisy image to get a decent looking denoised results, to remove the noise we can rearange the equation above to solve for x_0:






Notice how at large noise levels the Campanile starts to look like a completely different tower.
By implementing the following equation 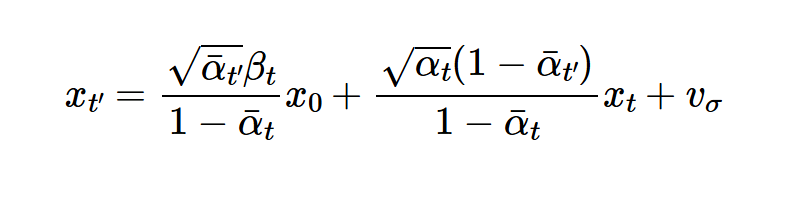 we create an iterative step denoising, where x_0 is prediction of a clean image.
Now we can go through our strided_timesteps - list of noise levels t=[990,960,...,30,0] to progressively denoise the image and get clean result:
we create an iterative step denoising, where x_0 is prediction of a clean image.
Now we can go through our strided_timesteps - list of noise levels t=[990,960,...,30,0] to progressively denoise the image and get clean result:








As we can see iterative denoising produces the cleanest and most detailed result, however it has also created some new data which wasnt in the original image.
Now if we denoise not from an image with noise applied to it, but from a pure noise, we can get some arbitrairly generated images like those below:





Previous results were alright, but we can make them better by reducing our image diversity. In previous part we only had conditioned noise, now we can mix some unconditional noise into that noise to get better looking results. I used the gamma 7 for the following equation to generate noise: noise = uncond_noise + gamma * (cond_noise - uncond_noise). Here are the generated images of higher quality:





If we add noise to some original image we can make edits to that existing image by iteratively denoising, the amount of noise will determine the amount of generated information/how far the denoised image is from original.






Notice how the image at i_start=1 doesnt match at all, because at i_start=1 it is just denoising nearly fully noise.
img2img when run on me:







img2img when run on lego figuringe:







We can provide the sketch of an image and denoise it using cfg, it will create an image roughly trying to match the sketch.
img2img when run on image from the web(from research paper):







img2img when run on hand drawn image:







img2img when run on hand drawn image:







Now if we mask out some area of the image and only denoise that, we can practically generate only that part of the image, redraw some part of it. Here are some of my results doing that:
Test image:




Me(lol):







Lego figurine:




We can generate images starting from some image but conditioned on some prompt, to make the image look somewhat like a prompt:
when run on test image with rocket ship prompt:






when run on flower with skull prompt:







when run on lego figurine with a man in hat prompt:







We can generate two noises and then combine them in a way to generate visual anagrams. Here we are generating one noise regularly and another one on the flipped image, we when flip the second noise and average the two noises. One noise is generating image normally and another generating noise for flipped image, we end up with a nice visual anagram:
Anagram of "an oil painting of people around a campfire" and "an oil painting of an old man"


Anagram of "an oil painting of a snowy mountain village" and "an oil painting of an old man"


Anagram of "a photo of a man" and "a photo of a dog"


By doing the same thing we did last time but running our noises through low and pass filter before combining them we can create hybrid image effect:
Hybrid of litograph of a skull and litograph of a waterfall


Hybrid of a man and a dog

Hybrid of a pencil and a rocket

Hybrid of a dog and hipster barista

By implementing unet given in the spec we can create a one step denoiser by training it on MNIST dataset, we grab and image from the dataset, noise it to sigma=0.5 level and let the model try to predict that, using l2 norm as our metric.
Here is what the noise process for dataset images looks like:







Now we train on sigma=0.5:
Here is how it performs on in-distrubution tests at 1st epoch



Here is how it performs on in-distrubution tests at 5th epoch



Here is how it performs on out of distrubution tests at 5th epoch











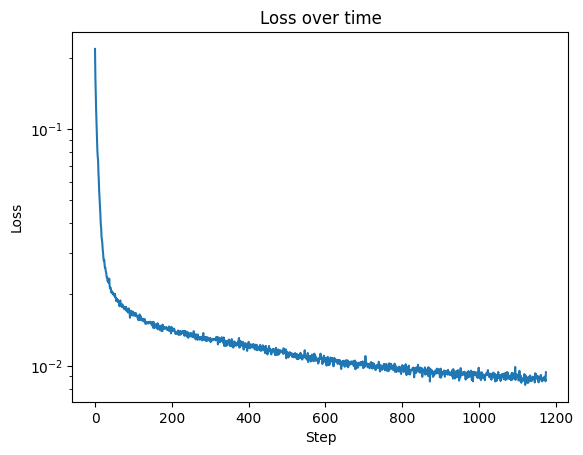
Now we implement time conditioning, and using equations from part A of the project we train the model to detect noise, we then sample like we did in part A.
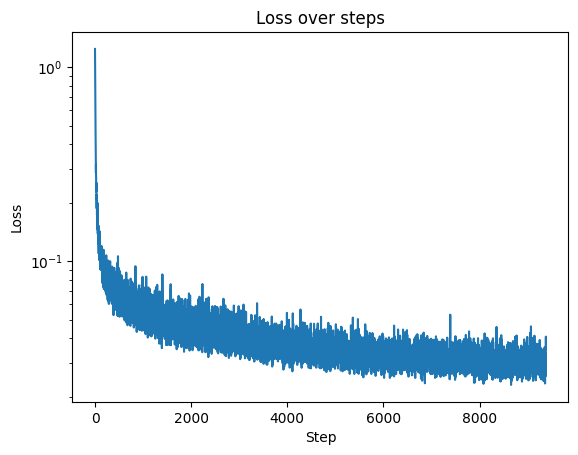
Here is the loss curve:
Here are the results after training:


We can now pass the digit associated with the image for the model to learn to generate specific digits. 10% of the time we pass an empty conditioning array to make unet work without it being conditioned as well as make it be able to do classifier free guidance.
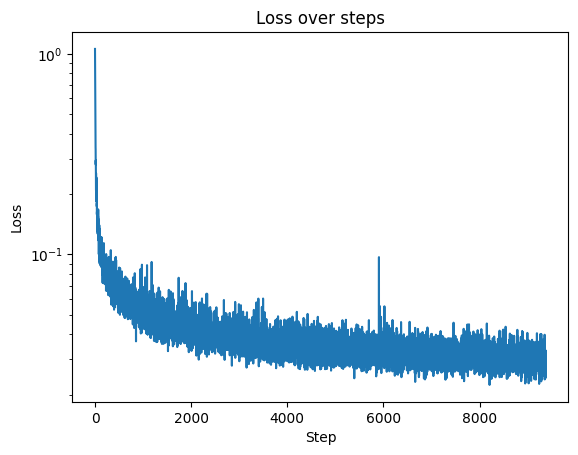
Here is the loss curve:
Here are the results after training:

